
Under the Hood: The Hidden Software Architecture and Hardware Engineering Behind the Food AI Revolution
Computer vision challenges, inference budgets, and the invisible infrastructure Past the Market Hype
NEW TECNOLOGY
By Marcelo Salamon
6/30/20266 min read

Abstract: Implementing artificial intelligence within the food ecosystem goes far beyond digital marketing gimmicks, standing as a highly complex software and hardware engineering hurdle. This paper breaks down the deep learning architectures driving modern computer vision systems, focusing on the hybrid integration of Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), alongside rapid inference frameworks like YOLO. It examines critical engineering bottlenecks in segmenting overlapping instances, the infrastructure economics of cloud computing versus edge processing, and the governance challenges and MLOps costs faced by the industry. Ultimately, this analysis demonstrates that the real driving force for technical innovation and capital investment lies in optimizing back-end and industrial infrastructure, rather than consumer-facing applications.
Keywords: Computer Vision; Convolutional Neural Networks; Vision Transformers; Inference Costs; MLOps.
Introduction
Modern headlines often oversimplify the impact of artificial intelligence, relying on the marketing trope that AI is "changing our relationship with food." However, from a strict computer engineering and data science standpoint, this narrative glosses over the fundamental infrastructure layers required to keep these systems online. Processing biological and gastronomic data is not a straightforward extension of traditional deep learning models. Instead, it presents an environment of extreme morphological variability and computational complexity that strains current hardware and software architectures.
This paper deliberately bypasses product design and user interfaces to dissect the underlying technical engine that makes pattern recognition in complex images possible, the training pipelines of neural networks, and the financial sustainability of production systems. The primary focus is to understand how classic computer vision and massive data-processing problems are solved in dynamic, low-latency environments, and why algorithmic efficiency combined with hardware choice dictates whether a product succeeds commercially or fails structurally.
The Computer Vision Challenge: Morphological Data Variability
Binary or multiclass classification on standardized datasets, such as sorting pictures of cats and dogs, represents the introductory stage of machine learning. In those scenarios, translation, rotation, and scale invariances are handled well by traditional convolutional networks. However, food recognition introduces a severe conceptual flaw: the absolute lack of a fixed topology or geometry. A single dish can display radically different visual signatures depending on environmental lighting ($I$), camera capture angle ($\theta$), object occlusion ($O$), and spatial noise, such as utensils or cast shadows.
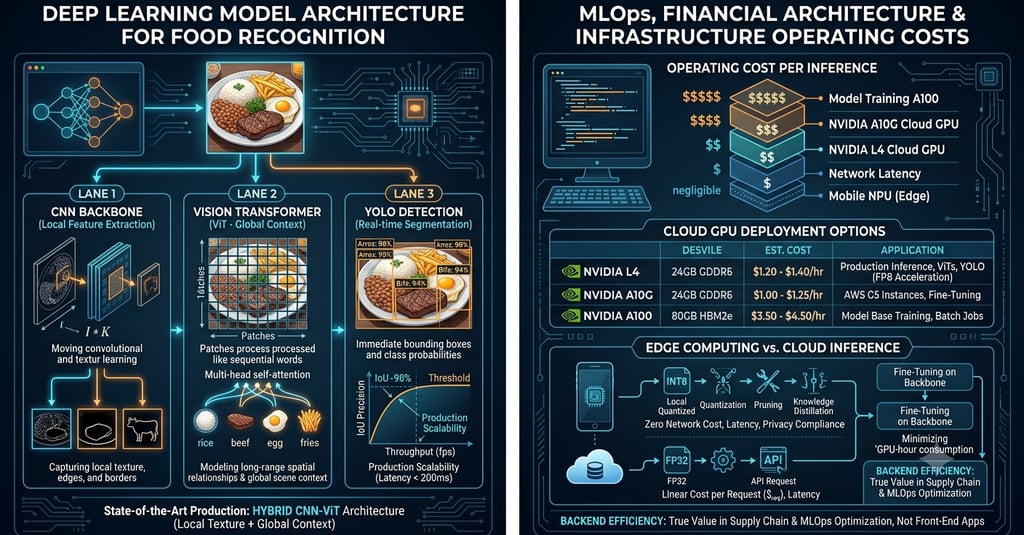
To mathematically model this variability, systems engineers build processing pipelines that combine two main architectural families:
Convolutional Neural Networks (CNNs)
CNNs serve as the foundation for low-grain image processing. By repeatedly applying convolutional filters, these networks extract local geometric primitives, such as edges, texture gradients, and spatial contours. The massive advantage of CNNs lies in weight sharing and pooling mechanisms, which guarantee computational efficiency in the initial feature-extraction layers. Mathematically, the convolution operation on a two-dimensional image $I$ with a kernel $K$ is expressed as:
$$S(i,j) = (I * K)(i,j) = \sum_{m} \sum_{n} I(i-m, j-n) K(m,n)$$
Even so, CNNs struggle to capture long-range dependencies due to the limited receptive field of their local convolutional filters.
Vision Transformers (ViTs)
To overcome the contextual limitations of CNNs, Vision Transformers treat the pixel matrix similarly to text sequences. The image is broken down into multiple rigid patches (for instance, $16 \times 16$ pixel matrices), which are flattened and linearly projected into an embedding space. The self-attention mechanism maps global correlations among these patches, enabling the model to identify spatial relationships between different components placed at opposite ends of the visual matrix. The attention function relies on Query ($Q$), Key ($K$), and Value ($V$) matrices, calculated as:
$$\text{Attention}(Q, K, V) = \text{softmax}\left( \frac{Q K^T}{\sqrt{d_k}} \right) V$$
Where dk represents the dimension of the keys, serving as a scaling factor to prevent gradient saturation within the softmax function.
Engineering Note: Hybrid (CNN-ViT) architectures represent the current state-of-the-art in production systems. Convolutional layers compress the initial image dimensionality and extract local textures, while Transformer blocks process the resulting feature map to consolidate macro-context understanding.
Real-Time Detection and Segmentation
Simply performing macro classification ("This is food") is not enough for complex analytical systems. The architecture requires object detection (bounding boxes) and instance segmentation. For applications demanding low latency (under 200ms), the industry standard points to the YOLO (You Only Look Once) model family.
Unlike two-stage architectures (such as R-CNN or Mask R-CNN) that first generate regions of interest and then classify them, YOLO frames detection as a single regression problem. A single forward pass through the network simultaneously predicts bounding box coordinates and class probabilities for each cell in a grid overlaid on the image. This design trades small fractions of IoU (Intersection over Union) precision for massive frame throughput, enabling real-time processing directly within a mobile device's video stream.
The biggest engineering bottleneck arises during heavy target overlapping or mixed ingredients. In these environments, traditional semantic segmentation techniques collapse, requiring engineers to train specialized sub-networks for unsupervised volumetric estimation to deduce actual portion sizes without a physical, stochastic reference object.
Financial Architecture and MLOps: The Cost of Scale
Machine learning engineering for large-scale products is bound by infrastructure budgets and cloud computing constraints. Developing computer vision solutions requires meticulous planning of the inference pipeline and re-training cycles (MLOps).
Computational power allocation varies drastically between the baseline model training phase and the production runtime environment (inference). The cloud computing hardware options commonly deployed across corporate architectures break down into the following operational items:
NVIDIA L4 Instance Profile
VRAM: 24GB GDDR6
Estimated Cost: $1.20 to $1.40 per hour
Engineering Application: Optimized for running ViTs and YOLO models in production environments. It offers excellent energy efficiency and native FP8 acceleration.
NVIDIA A10G Instance Profile
VRAM: 24GB GDDR6
Estimated Cost: $1.00 to $1.25 per hour
Engineering Application: Standard across cloud environments (such as AWS G5 instances). It is primarily used for concurrent inference and medium-scale fine-tuning pipelines.
NVIDIA A100 Instance Profile
VRAM: 80GB HBM2e
Estimated Cost: $3.50 to $4.50 per hour
Engineering Application: Restricted to training vision models from scratch and processing massive corporate datasets in large batches.
To avoid prohibitive cloud bills that would tank consumer-facing software, engineering teams rarely build proprietary architectures from scratch. The standard methodology is to pull pre-trained vision backbones from open repositories like Hugging Face (such as ResNet, ConvNeXt, or DeiT variants) and execute a Fine-Tuning process. This approach restricts re-training to the final dense layers of the classifier (the head), minimizing GPU-hour consumption and focusing core computational resources on proprietary, regional target datasets.
Edge Computing vs. Cloud Infrastructure
Relying strictly on cloud GPU clusters introduces a linear cost per request (Creq), threatening the financial scalability of smart tracking devices and analytical software. As an answer to this economic bottleneck, systems engineering has pivoted heavily toward Edge Computing.
Moving the model to local runtime environments on a user's smartphone or dedicated microcontrollers (like ARM Cortex-M architectures or mobile Neural Processing Units - NPUs) requires aggressive neural network compression methods:
Quantization: Scaling down network weights from 32-bit floating-point precision (FP32) to 8-bit integers (INT8). This technique slashes memory consumption by up to 75% and drastically boosts inference speed on local NPUs, with only a marginal loss in precision that rarely impacts final production accuracy.
Pruning: Stripping away synapses and neurons whose mathematical weights hover close to zero and do not contribute significantly to the activation of subsequent layers, resulting in lighter, sparse matrices.
Knowledge Distillation: Training a compact "student" network to mimic the output probability distributions of a massive, complex "teacher" network.
By processing images locally, the enterprise eliminates network latency, mitigates data privacy compliance risks (such as GDPR and regional data privacy laws), and drops central cloud inference costs to zero.
The Invisible Back-End: Where the Capital Flows
While consumer mobile apps and fitness trackers capture public attention, an analysis of venture capital and corporate spending reveals that true technical innovation is happening across B2B industrial supply chains. Computer vision AI has found its most mature and profitable applications integrated directly into manufacturing lines, logistics, and warehouse distribution networks.
On automated production lines, high-speed industrial cameras capture frames under studio-controlled lighting. Within this standardized environment, computer vision models run inferences in milliseconds to perform automated quality inspections. Algorithms execute semantic segmentation to identify anomalies, minute color shifts indicating structural degradation, foreign objects, or sterile packaging failures. This processing happens at the firmware level on highly reliable embedded systems.
Furthermore, blending inventory vision data with time-series predictive models (such as LSTM recurrent networks or advanced linear frameworks) allows companies to optimize demand forecasting across distribution hubs. The technology, therefore, prevents raw material waste at the source, proving that the most robust and profitable AI in the market runs completely hidden from the end consumer.
Conclusion
The engineering behind artificial intelligence systems applied to target mapping and object recognition shows that a tech product's success does not depend on the abstract sophistication of its models, but on its ability to coordinate algorithmic efficiency, hardware constraints, and data governance. The immense morphological complexity of real-world targets requires advanced architectural setups, combining the local strengths of CNNs with the global context capabilities of Vision Transformers, without sacrificing the operational speeds delivered by single-pass architectures like YOLO.
The ongoing industry transition highlights a definitive shift toward decentralized processing via Edge Computing. By optimizing large models using quantization and pruning to run on local edge hardware, systems engineers remove the financial burden of cloud computing. Ultimately, AI adoption in this market will solidify through mature MLOps pipelines and invisible back-end automation, showing that the underlying engineering engine is far more complex and compelling than commercial front-ends suggest.
Technical References
DOSOVITSKIY, Alexey et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv preprint arXiv:2010.11929, 2020.
REDMON, Joseph et al. You Only Look Once: Unified, Real-Time Object Detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 779-788.
LECUN, Yann; BENGIO, Yoshua; HINTON, Geoffrey. Deep Learning. Nature, v. 521, n. 7553, pp. 436-444, 2015.
NVIDIA CORPORATION. NVIDIA L4 Tensor Core GPU Datasheet: Next-Generation Compute for AI and Video Inference. Santa Clara: NVIDIA, 2023.
Contact
Contact us for questions or suggestions
contact@turingvision.com
fone: + 55 54 99122 0659
© 2026. All rights reserved. https://turingsvision.com/privacy-policy